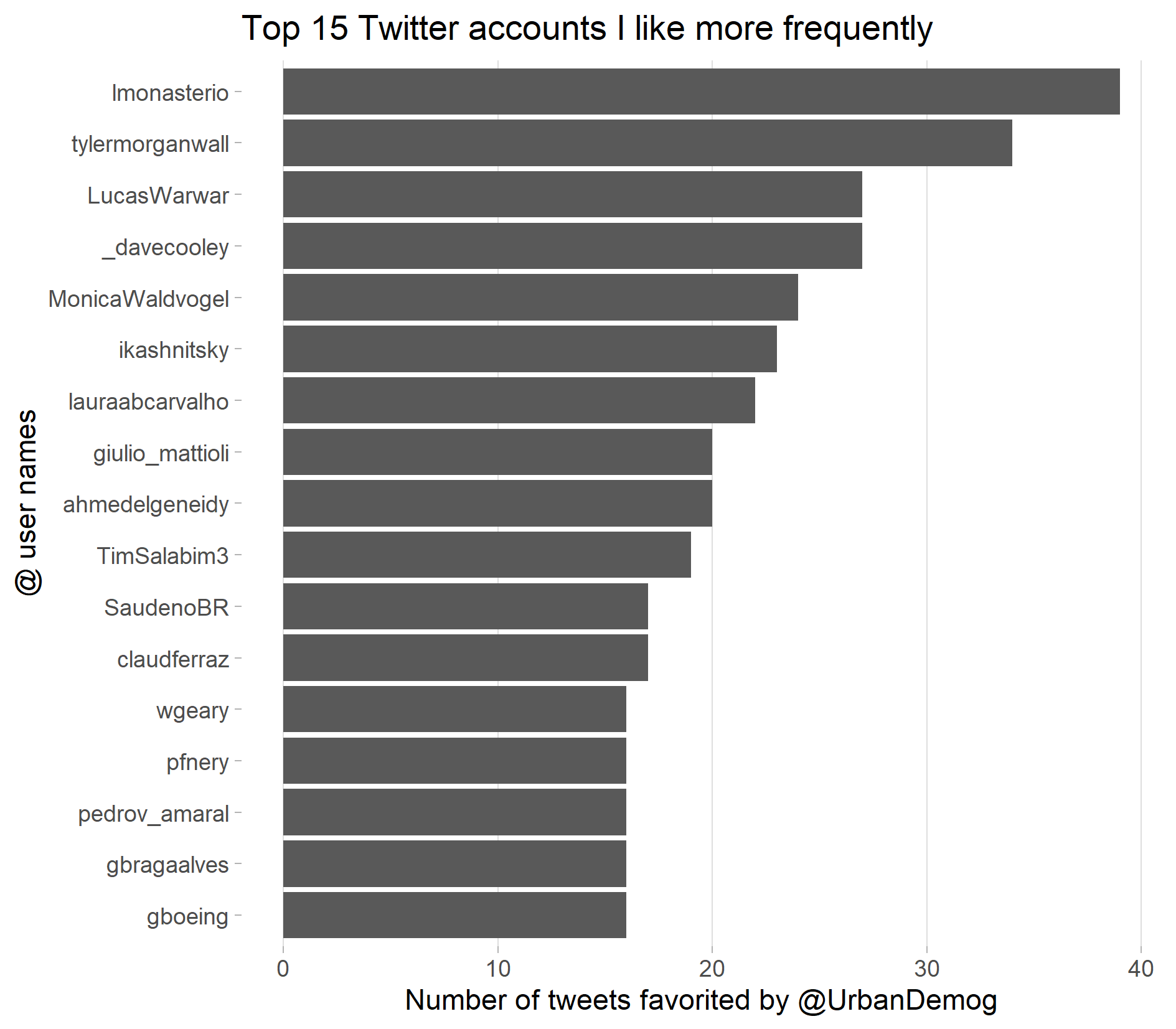
Top favorited tweets
Here is a 2-minute procrastination exercise in
. This a very short script that allows you to download the data on all previous 3K tweets you favorited and find out the tweeps you like the most. This post was inspired by
Fernando Barbalho, who shared an original version of this code on his
Github.
The first thing to do is to load a few libraries and download the tweets favorited by a Twitter account:
library(rtweet)
library(magrittr)
library(ggplot2)
library(dplyr)
# download the data
df_favorites <- rtweet::get_favorites("@UrbanDemog", n=3000)
Count the number of favorited tweets by user:
users_favorite <-
df_favorites %>%
group_by(screen_name, user_id) %>%
summarise(quant_fav = n())
Now you can filter the top ‘n’ users using the super handy dplyr::top_n function and plot the results on chart like this:
# filter top 15 users
users_favorite %>%
ungroup() %>%
top_n(15,quant_fav) %>%
mutate(screen_name = reorder(screen_name,quant_fav)) %>%
# plot
ggplot() +
geom_col(aes(x = screen_name, y = quant_fav)) +
theme_light() +
theme(panel.grid.major.y = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank()) +
coord_flip() +
labs(title = "Top 15 Twitter accounts I like more frequently",
y = "Number of tweets favorited by @UrbanDemog",
x = "@ user names")